
Anthropic is struggling to keep up with its own viral moment (and that’s a problem for my clients)
Anthropic acknowledged recent problems, but two published "issues" were choices and only one was an actual bug. Ongoing Claude outages emphasize the need to access project context across platforms.

It’s 2:49 PM on a Tuesday and I’m staring at a “Can’t reach Claude” screen for the third time this week.
I took a photo of it to capture the feeling of staring at an error screen when you’re trying to be productive and trying to meet a build deadline. Then I pulled up the Claude.ai status page and the yellow/red bars tell a story. Summaries across the board: claude.ai and Claude Cowork show “Major Outage”; the API and Claude Code show “Partial Outage.” Once upon a time there were green fields of bars representing better service, which gave to way to more and more red, clustering toward the right edge, toward now. A small forest of angry red lines that I’m certain also represent frustrated Claude users.
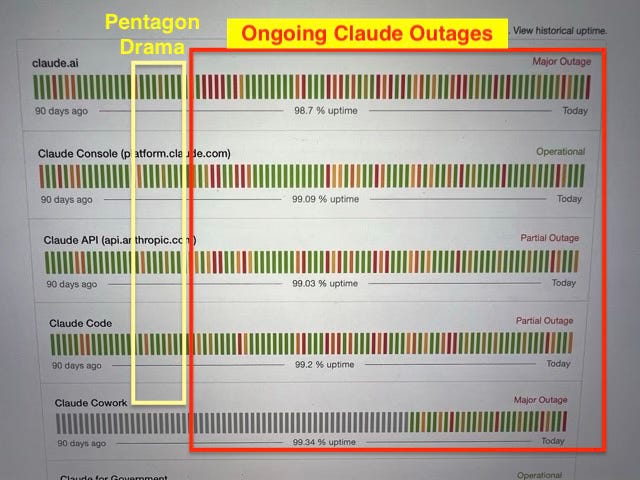
We could try to be generous and say they had a bad week, but I think this is actually revealing a patten that doesn’t have a clear solution in near sight.
I’ve been a Claude user for a while and a paying subscriber for the Claude 20x Max subscription. I run my consulting practice (AI strategy and building workflow automations for mid-market organizations) on Claude. I don’t use Claude as just as a chat interface. I use Claude as my main agentic AI command seat. I have a fleet of servers running Claude-powered agents that handle my pipeline management, my project task management, my code reviews, my content scheduling, my event discovery, my presentation drafts, my client communication drafts. Claude is infrastructure for me, not a toy. These tremors in the infrastructure present risks to my business.
Here’s what I think happened, why it matters beyond the outrage cycle that already played out on X and Reddit, and how I am responding for myself and my clients with custom MCP server infrastructure.
The demand curve went vertical
In mid-February 2026, Anthropic ended up in the center of a controversy involving the Pentagon. I’m not going to relitigate that story here, but the consequences of this massive new cycle spotlight was visible: a significant wave of new users showed up on Claude, drawn by the news coverage. Some came out of curiosity. Some came because the controversy demonstrated that Anthropic was playing at a level where its decisions had national-security implications. Some came because they felt that Anthropic took a righteous moral high-ground by drawing the line at AI for autonomous weapon (even though Claude models were already being used by Palantir and the US military in planning strikes on Iran. And if you don’t know who Palantir is, have fun going down that rabbit hole of dystopian surveillance technology.) Either way, the user base grew fast.
Anthropic’s infrastructure was already stretched. They told Fortune directly: “Demand for Claude has grown at an unprecedented rate, and our infrastructure has been stretched to meet it, particularly at peak hours.” Public admissions confirming that Anthropic cannot keep up with its own growth. They signed a $25 billion deal with Amazon for 5 gigawatts of compute capacity, but infrastructure of that scale doesn’t come online right away. Antrhopic claims this deal should yield meaningful compute in the next three months and should add nearly 1 gigawatt of compute power before the end of the year (the equivalent of an entire nuclear reactor.) In the meantime, every agentic session — every Claude Code run, every multi-turn API call — burns inference compute at rates that that Anthropic’s current infrastructure was not designed to absorb.
The degradation that wasn’t just a bug
Starting in early March, developers started noticing something off. Claude Code was reading code less and rewriting files more. It was abandoning tasks mid-way. It was forgetting what it had decided ten minutes earlier in the same session, repeating steps, making inconsistent tool choices. Usage limits were draining faster than they should have been.
Stella Laurenzo, Senior Director in AMD’s AI group, did what engineers do when they think something is wrong: she pulled the data. 6,852 Claude Code session files. 234,000 tool calls. 17,871 thinking blocks. Her analysis documented a 67% drop in reasoning depth from where it had been in January. Claude Code was reading code three times less than before and rewriting files at twice the rate. Task abandonment was happening at rates that were previously nonexistent. She published the raw data on GitHub in April and her post spread fast.
Independent benchmarks corroborated it. BridgeMind re-tested Claude Opus 4.6 and found accuracy had dropped from 83.3% to 68.3% — a ranking fall from #2 to #10.
Anthropic eventually published a postmortem on April 23. They identified three changes that had degraded performance. This is where it gets interesting.
Only one of the three “bugs” was an actual bug.
The first change: reducing Claude Code’s default reasoning effort from high to medium. This was a deliberate decision made on March 4, ostensibly to reduce UI latency. The model would think less, respond faster, and the interface wouldn’t appear frozen while it worked. Anthropic acknowledged it was “the wrong tradeoff” and reverted it on April 7. But that’s 34 days of deliberately reduced reasoning shipped to users without announcement. As one analyst put it: “Lowering the reasoning effort default from high to medium was an intentional tradeoff, one Anthropic even publicly justified.” Changing default reasoning effort settings to medium wasn’t a bug. That was a choice.
The second change (a caching optimization on March 26) actually was a bug. Code that was supposed to clear idle session context once ended up clearing it every turn, making Claude forget its own reasoning mid-session. That explains the forgetfulness, the repetition, the fast token drain. Real bug, real fix.
The third change: a system prompt addition on April 16 capping responses at 25 words between tool calls. This was also intentional. Anthropic was trying to reduce verbosity. Subsequent testing found it caused a 3% performance drop in coding quality. It shipped with Opus 4.7 and was reverted four days later.
The postmortem calls all three “issues,” which glazes over an important distinction: performance degradation resulted from at least two intentional tradeoffs and one actual bug.
The model behavior I’ve been living with
This is where I can speak from direct experience rather than secondhand reporting.
I’ve been using Opus 4.7 since it launched, and I honestly haven’t had any “aha!” moments that made me feel like Opus 4.7 is a legitimate upgrade from Opus 4.6.
Verbosity is up. Default responses are longer and chattier than 4.6, which is ironic given the verbosity cap they shipped and then yanked. The researchers noted the increased verbosity in the Opus 4.7 system card. I tried adjusting my system prompts, but the bandaid solution I’ve settled on is usually turning on “concise” response mode to temper the verbosity. It’s better but still not perfect.
The other pattern that keeps showing up: the model asserts assumptions instead of checking what’s available. Tools on the table, files in the project, logs accessible — it frequently still constructs an answer from inference rather than just looking at the actual data. I’ve caught myself multiple times saying “did you actually check that?” And the initiative is erratic — sometimes it won’t act without explicit permission on something trivial, then in the same session it’ll complete three tasks I didn’t ask for after it blows past its own clarifying question that it didn’t give me a chance to answer.
The other key “feature” they introduced is “Adaptive Thinking” toggle, which lets the model choose whether to turn on extended reasoning or not. This allows Anthropic to reduce their overall server loads by removing the user’s ability to use extended thinking and reasoning on all tasks. The practical consequence of letting the model router decide reasoning depth is that the user has less control over whether Opus 4.7 will reason deeply about important queries.
Anthropic creates excellent models, but the issue is that they are currently nerfing model performance to allow more users to jump onboard, thereby spreading mediocre performance for everyone. Claude models are excellent when they’re at peak performance, but right now (in May 2026) I can’t in good conscience recommend the Claude.ai platform to my clients for production workflows. Not because the models are bad, but because the platform reliability and the behavior consistency aren’t where they need to be for me to stake a client relationship on them.
How I’m responding
I’ve been building toward this for a while without fully naming it: I need to own my project context and make my toolsets portable.
I run custom MCP server infrastructure that coordinates my models and coding agents across a fleet of 7 computers in my office. My custom MCP servers let me operate across different AI interfaces. After initially clinging to Claude out of habit and fondness, I expanded my full Remote Fleet MCP workflow to run on ChatGPT, Perplexity, and LibreChat (a self-hosted open source AI chat platform.) I’m also slowly building a fully local version that runs on my own GPUs. The goal is to never be fully dependent on any single provider’s uptime, pricing decisions, or silent model changes.
This is where I think the industry is heading anyway. By the end of 2026, I think local models are going to be a serious player — not for every use case, but for the ones where you need consistency, privacy, and zero dependency on someone else’s infrastructure. Apple seems to be banking on exactly this with the M5 Max lineup: powerful enough local inference, on your own hardware, no API fees, no outages.
The AI frontier models are still ahead on the hardest reasoning tasks. But the gap is closing, and the infrastructure reliability argument for cloud providers is looking shakier than it did six months ago.
I still think Anthropic builds the best models. The care that goes into the research, the safety work, the documentation — it shows. But right now they’re in a painful in-between: too popular for their infrastructure and making quiet tradeoffs that erode the trust they’ve worked hard to build with developers.
The “Can’t reach Claude” screen above is a symptom. The question is whether they can scale fast enough to meet the demand before people like me finish building the exits and alternatives.
I run Morpheos LLC, an AI strategy and implementation consultancy. I build custom AI portals and agentic systems for mid-market and regulated organizations.